** 클린 아키텍처 소프트웨어 구조와 설계의 원칙 책을 읽고 작성한 글입니다.
SOLID 원칙이란?
SOLID 원칙은 함수와 데이터 구조를 클래스로 배치하고, 이 클래스들을 어떻게 결합할지에 대한 원칙입니다.
여기서 "클래스"는 OOP에만 국한된 개념이 아니라 데이터 + 함수 구조를 의미합니다.
SOLID 원칙은 모듈/컴포넌트 내부 수준(코드 레벨보다는 상위)에서 적용되며, 그 목적은 다음과 같습니다.
- 변경에 유연한 소프트웨어
- 이해하기 쉬운 소프트웨어
- 많은 소프트웨어 시스템에서 사용 가능한 컴포넌트 기반 구조
SOLID는 긴 역사를 거쳐 수많은 변경 끝에 다음 다섯 가지 원칙으로 정립되었습니다.
- SRP (Single Responsibility Principle): 소프트웨어 "각 모듈"의 변경 이유는 하나여야 함
- OCP (Open-Closed Principle): 수정에는 닫혀있고, 확장에는 열려있어야 함
- LSP (Liskov Substitution Principle): 상위 ↔ 하위 타입은 서로 치환 가능해야 함
- ISP (Interface Segregation Principle): 인터페이스는 용도에 맞게 세분화되어야 함
- DIP (Dependency Inversion Principle): 고수준 → 저수준 구현체를 직접 연결하지 않고 추상화를 통해 연결
이제 각 원칙을 자세히 살펴보겠습니다.
SRP: 단일 책임 원칙
[흔한 오해]
많은 사람들이 SRP를 "모든 모듈은 단 하나의 일만 해야 한다"고 이해하지만, 이는 정확하지 않습니다.
SRP의 진짜 의미는 "하나의 모듈은 오직 하나의 액터(actor)에 대해서만 책임져야 한다"는 것입니다.
(**액터란 소프트웨어 변경을 요청하는 이해관계자 집단을 의미)
소프트웨어 시스템은 사용자와 이해관계자를 만족시키기 위해 변경되므로,
변경의 이유는 결국 특정 액터의 요구사항 때문입니다.
또한 "응집성(Cohesion)"은 SRP를 암시하는 핵심 단어로,
단일 액터를 책임지는 코드를 함께 묶어주는 것이 바로 응집성입니다.
[징후 1] 우발적 중복
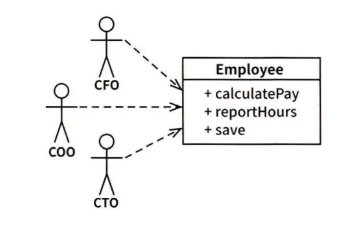
위 그림처럼 하나의 Employee 클래스에 CFO팀, COO팀, CTO팀이라는 서로 다른 3개의 액터가 결합되어 있다고 가정해봅시다.
문제는 CFO의 결정에 따른 코드 변경이 COO 팀이 의존하는 무언가에 영향을 줄 수 있다는 것입니다.
서로 다른 액터가 의존하는 코드를 너무 가까이 배치하면 이런 문제가 발생합니다.
[징후 2] 병합 충돌
소스 파일에 많은 메서드를 포함하면 병합 충돌이 자주 발생합니다.
예를 들어, CTO팀과 COO팀에서 동시에 Employee 클래스를 수정한다면 변경사항을 반영할 때 충돌이 발생하고,
CFO팀은 고래 싸움에 새우 등 터지는 격이 됩니다.
[해결책] 책임 분리
메서드를 각기 다른 클래스로 이동시켜야 합니다.
Step 1: 기존 구현 (문제 있는 코드)
class Employee:
def __init__(self, name, salary_level, hours):
self.name = name
self.salary_level = salary_level
self.hours = hours
# 책임 1: 급여 계산 (회계팀의 변경 이유)
def calculate_pay(self):
base_pay = self.salary_level * 1000
return base_pay * self.hours
# 책임 2: 근무 시간 보고서 (경영진의 변경 이유)
def report_hours(self):
print(f"{self.name} worked {self.hours} hours this week.")
# 책임 3: 데이터 저장 (IT팀의 변경 이유)
def save(self):
print(f"Saving {self.name} data to DB.")
Step 2: 액터에 따라 클래스 구분
# 1. 순수 데이터 구조
class EmployeeData:
def __init__(self, name, salary_level, hours):
self.name = name
self.salary_level = salary_level
self.hours = hours
# 2. 책임 1: 급여 계산만 담당
class PayCalculator:
def calculate_pay(self, data: EmployeeData):
base_pay = data.salary_level * 1000
return base_pay * data.hours
# 3. 책임 2: 보고서 출력만 담당
class HourReporter:
def report_hours(self, data: EmployeeData):
print(f"[Report] {data.name} worked {data.hours} hours.")
# 4. 책임 3: 데이터 저장만 담당
class EmployeeSaver:
def save(self, data: EmployeeData):
print(f"Saving {data.name} data to the database.")
하지만 이렇게 하면 개발자가 세 개의 클래스를 모두 추적해야 하는 번거로움이 생깁니다.
Step 3: 퍼사드 패턴 적용
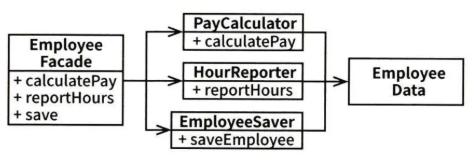
퍼사드 클래스는 코드가 거의 없고, 세 클래스의 객체를 생성한 뒤 요청된 메서드를 가진 객체로 위임하는 역할만 합니다.
class EmployeeFacade:
def __init__(self, data: EmployeeData):
self.data = data
self.calculator = PayCalculator()
self.reporter = HourReporter()
self.saver = EmployeeSaver()
def calculate_pay(self):
return self.calculator.calculate_pay(self.data)
def report_hours(self):
self.reporter.report_hours(self.data)
def save(self):
self.saver.save(self.data)
# 사용 (단순함)
data = EmployeeData("Bob", 6, 35)
facade = EmployeeFacade(data)
pay = facade.calculate_pay()
facade.report_hours()
facade.save()
Step 4: 중요한 책임은 기존 클래스에
개발자에 따라 중요한 비즈니스 로직은 데이터와 가깝게 위치시키고 싶을 수 있습니다.
이 경우 중요한 책임은 기존 클래스에, 나머지는 다른 클래스에 분리할 수 있습니다.
class Employee:
def __init__(self, name, salary_level, hours):
self.data = EmployeeData(name, salary_level, hours)
self.reporter = HourReporter()
self.saver = EmployeeSaver()
# 핵심 책임: 급여 계산은 Employee 자체가 수행
def calculate_pay(self):
base_pay = self.data.salary_level * 1000
return base_pay * self.data.hours
# 덜 중요한 책임: 다른 객체로 위임
def report_hours(self):
self.reporter.report_hours(self.data)
def save(self):
self.saver.save_employee(self.data)
결론
단일 책임 원칙은 중간 수준(메서드/클래스)의 원칙이지만,
컴포넌트 및 아키텍처 수준에서도 다른 형태로 다시 등장합니다.
(컴포넌트 수준에서는 공통 폐쇄 원칙, 아키텍처 수준에서는 경계를 책임지는 변경의 축)
OCP: 개방-폐쇄 원칙
소프트웨어 객체는 확장에는 열려있어야 하고, 변경에는 닫혀 있어야 합니다.
행위는 확장 가능해야 하지만, 이때 객체 자체의 변경은 없어야 합니다.
살짝 확장하는데 엄청난 수정이 필요하다면 그것은 엄청난 실패입니다.
OCP는 클래스와 모듈 설계뿐만 아니라 아키텍처 컴포넌트 수준에서 고려할 때 훨씬 중요한 의미를 가집니다.
[사고 실험] 재무제표 시스템
재무제표를 웹 페이지에 표시하는 시스템이 있다고 가정해봅시다.
- 데이터를 스크롤할 수 있고
- 음수는 빨간색으로 표시됩니다
이제 액터가 새로운 요청을 합니다.
"동일한 정보를 보고서 형태로 변환하고 흑백 프린터로 출력하고 싶습니다."
아키텍처가 훌륭하다면, 변경되는 코드의 양이 가능한 최소여야 합니다.
이를 위해서는 아래의 설계 원칙을 준수해야 합니다.
- 서로 다른 목적으로 변경되는 요소를 적절히 분리 (SRP)
- 의존성을 체계화 (DIP)
SRP를 적용하면 두 가지 책임으로 분리할 수 있습니다.
- 보고서 데이터 계산 책임
- 데이터를 웹/종이로 출력하는 책임
이렇게 분리했다면, 하나를 변경할 때 다른 하나가 영향받지 않도록 의존성도 조직화해야 합니다.
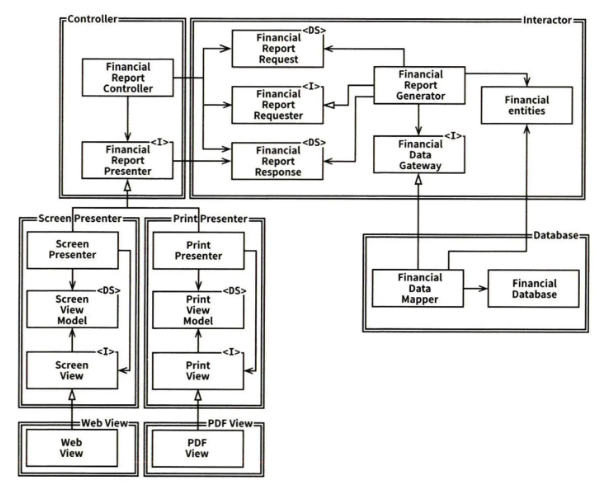
위 그림에서
- 닫힌 화살표: 구현, 상속 관계
- 열린 화살표: 사용 관계
- 모든 의존성이 소스코드 의존성을 나타냄
- Mapper는 구현 관계를 통해 Gateway를 알지만 Gateway는 Mapper에 대해 아무것도 모름
- 이중선은 한 방향으로만 교차 (모든 컴포넌트 관계는 단방향)
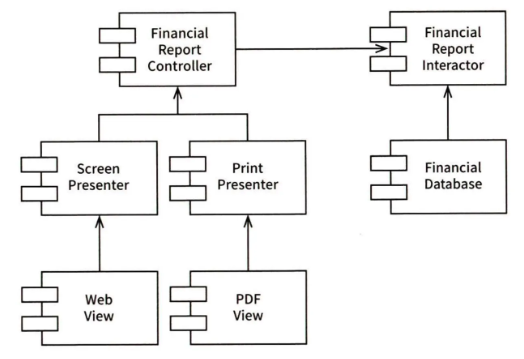
위 그림에서 각 화살표는 변경으로부터 보호하려는 컴포넌트를 향하도록 그려져 있습니다.
이에 따르면, Interactor가 가장 보호받아야 합니다. (Interactor > Controller > Presenter > View)
비즈니스 로직을 담당하고 가장 높은 수준의 정책을 포함하기 때문입니다.
정보 은닉
FinancialReportRequester는 방향성 제어와는 다른 목적을 가집니다.
컨트롤러가 인터렉터 내부에 대해 너무 많이 알지 못하도록 하기 위해 존재합니다.
만약 이 인터페이스가 없다면,
- 컨트롤러 → 제너레이터 → 엔티티 방향으로 추이 종속성 발생
- 추이 종속성은 "엔티티는 자신이 직접 사용하지 않는 요소에 절대로 의존해서는 안 된다"는 소프트웨어 원칙 위배
즉, 이 인터페이스는
- 컨트롤러 변경으로부터 인터렉터를 보호 (우선순위 가장 높음)
- 인터렉터 변경으로부터 컨트롤러를 보호 (인터렉터 내부를 은닉)
코드 예시
아래는 Gemini를 통해 생성한 컴포넌트들의 파이썬 예시 코드입니다.
from abc import ABC, abstractmethod
from typing import List, Dict, Any
# ----------------------------------------------------
# DIP: High-level modules should not depend on low-level modules.
# Both should depend on abstractions (interfaces).
# ----------------------------------------------------
class FinancialDataGateway(ABC):
"""
Financial Report Generator가 의존하는 추상 인터페이스 (High-level Abstraction).
데이터 접근 방식(Mapper)에 대한 구체적인 구현을 분리합니다.
"""
@abstractmethod
def fetch_financial_data(self) -> List[Dict[str, Any]]:
"""재무 데이터를 가져옵니다."""
pass
class FinancialDataMapper(FinancialDataGateway):
"""
Financial Database에 직접 접근하는 저수준 모듈의 예시.
데이터베이스 연결 및 매핑 로직을 담당합니다.
(여기서는 단순한 Mock 데이터 사용)
"""
def __init__(self, database_connection_info: str):
# 실제 환경에서는 여기서 데이터베이스 연결 설정이 이루어집니다.
self.db_info = database_connection_info
print(f"Data Mapper initialized with: {self.db_info}")
def fetch_financial_data(self) -> List[Dict[str, Any]]:
"""데이터베이스에서 데이터를 가져오는 것을 시뮬레이션합니다."""
print("-> FinancialDataMapper: Fetching data from database...")
return [
{"entity": "Company A", "revenue": 100000, "expenses": 50000},
{"entity": "Company B", "revenue": 200000, "expenses": 80000}
]
# OCP 예시를 위한 또 다른 데이터 소스 (예: 외부 API)
class ExternalApiGateway(FinancialDataGateway):
"""
OCP: 새로운 데이터 소스를 추가할 때 Generator 코드를 수정할 필요가 없습니다.
"""
def fetch_financial_data(self) -> List[Dict[str, Any]]:
print("-> ExternalApiGateway: Fetching data from external API...")
return [
{"entity": "Company C", "revenue": 50000, "expenses": 10000}
]
class FinancialReportGenerator:
"""
FinancialDataGateway 추상화에 의존하는 High-level 모듈.
데이터를 가져오는 구체적인 방식(Mapper)에 대해서는 알 필요가 없습니다. (DIP)
"""
def __init__(self, data_gateway: FinancialDataGateway):
# DIP: 구체적인 클래스(Mapper)가 아닌 인터페이스(Gateway)에 의존
self._data_gateway = data_gateway
def generate_report(self, report_type: str) -> str:
"""
주어진 게이트웨이를 사용하여 데이터를 가져와 보고서를 생성합니다.
"""
print(f"\n--- Generating '{report_type}' Report ---")
# 데이터를 가져오기 위해 추상화된 메서드를 호출
data = self._data_gateway.fetch_financial_data()
report_lines = [f"Financial Report ({report_type})"]
total_profit = 0
for item in data:
profit = item["revenue"] - item["expenses"]
total_profit += profit
report_lines.append(
f" Entity: {item['entity']}, Revenue: {item['revenue']:,}, Expenses: {item['expenses']:,}, Profit: {profit:,}"
)
report_lines.append(f"\nTotal Profit Across Entities: {total_profit:,}")
return "\n".join(report_lines)
if __name__ == "__main__":
# ----------------------------------------------------
# Case 1: Database Report (using FinancialDataMapper)
# ----------------------------------------------------
# Low-level 구현체 생성 (Mapper)
database_mapper = FinancialDataMapper("PostgreSQL Connection String")
# High-level 모듈 생성 시, Mapper를 Gateway 인터페이스로 주입 (DIP)
database_generator = FinancialReportGenerator(database_mapper)
# 보고서 생성
report_db = database_generator.generate_report("Database Source")
print(report_db)
print("\n" + "="*50 + "\n")
# ----------------------------------------------------
# Case 2: External API Report (using ExternalApiGateway)
# ----------------------------------------------------
# OCP: Generator 코드를 수정하지 않고 새로운 데이터 소스 추가 (ExternalApiGateway)
api_gateway = ExternalApiGateway()
# 동일한 FinancialReportGenerator에 다른 Gateway 구현체를 주입
api_generator = FinancialReportGenerator(api_gateway)
# 보고서 생성
report_api = api_generator.generate_report("External API Source")
print(report_api)
위 예시 코드에서는 추상화된 Gateway 인터페이스를 통해 Generater에서 Mapper로의 직접적인 의존을 막을 수 있습니다.
또한 새로운 데이터 소스가 추가되어도 Generater 클래스는 수정이 필요없기 때문에 데이터 소스 추가는 독립적으로 가능합니다.
정리하면,
- Generator는 변경되지 않음 (변경에 닫혀있음)
- 새로운 데이터 소스가 추가 (확장에 열려있음)
- DIP를 통해 OCP를 달성 (추상화에 의존)
결론
OCP의 목표는 시스템을 확장하기 쉬운 동시에 변경으로 인한 영향을 최소화하는 데 있습니다.
저수준 변경으로부터 고수준을 보호할 수 있는 형태로 의존성 계층구조가 만들어져야 합니다.
LSP: 리스코프 치환 원칙
하위 타입의 정의
S 타입의 객체 o1 각각에 대응하는 T 타입 객체 o2가 있고, T 타입을 이용해서 정의한 모든 프로그램 P에서 o2의 자리에 o1을 치환하더라도 P의 행위가 변하지 않는다면, S는 T의 하위 타입이다.
LSP 준수 예시: 상속을 사용하도록 가이드
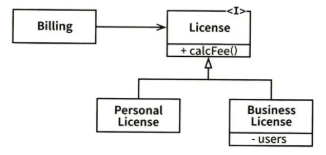
/**
* License 인터페이스: 모든 라이선스 타입의 비용 계산 계약을 정의합니다.
* Billing 모듈은 이 인터페이스에만 의존합니다.
* (다형성 및 의존성 역전 원칙 적용)
*/
public interface License {
/**
* 라이선스 비용을 계산합니다.
* @return 계산된 비용
*/
double calcFee();
}
public class PersonalLicense implements License {
private static final double BASE_FEE = 50.0;
@Override
public double calcFee() {
// 개인 라이선스는 고정된 기본 비용을 반환합니다.
return BASE_FEE;
}
}
public class BusinessLicense implements License {
// 다이어그램에 표시된 -users 필드 (private)
private final int users;
private static final double FEE_PER_USER = 10.0;
private static final double MAINTENANCE_FEE = 100.0;
public BusinessLicense(int users) {
this.users = users;
}
@Override
public double calcFee() {
// 사용자 수에 따른 비용과 기본 유지보수 비용을 합산합니다.
return (this.users * FEE_PER_USER) + MAINTENANCE_FEE;
}
}
/**
* Billing 클래스: 라이선스 객체를 받아 총 비용을 청구합니다.
* 오직 License 인터페이스에만 의존합니다.
*/
public class Billing {
/**
* 특정 라이선스의 비용을 계산합니다.
* License가 어떤 구체적인 타입(Personal, Business)이든
* calcFee()를 호출하여 처리할 수 있습니다.
* (리스코프 치환 원칙 준수)
*/
public double processBilling(License license) {
System.out.println("결제 프로세스를 시작합니다...");
// license 객체의 실제 타입에 따라 BusinessLicense.calcFee() 또는
// PersonalLicense.calcFee() 중 하나가 실행됩니다.
double fee = license.calcFee();
System.out.printf("계산된 라이선스 비용: %.2f\n", fee);
return fee;
}
}
public class LicenseApp {
public static void main(String[] args) {
Billing billingService = new Billing();
// 1. 개인 라이선스 객체 생성
License personal = new PersonalLicense();
// Billing 서비스에 개인 라이선스를 전달
System.out.println("--- 개인 라이선스 청구 ---");
billingService.processBilling(personal);
// 출력: 계산된 라이선스 비용: 50.00
System.out.println("\n--------------------------\n");
// 2. 비즈니스 라이선스 객체 생성 (10명 사용자)
License business = new BusinessLicense(10);
// Billing 서비스에 비즈니스 라이선스를 전달
System.out.println("--- 비즈니스 라이선스 (10명) 청구 ---");
billingService.processBilling(business);
// 출력: 계산된 라이선스 비용: 200.00 (10*10 + 100)
System.out.println("\n--------------------------\n");
// 핵심: 만약 새로운 'EnterpriseLicense'가 추가되더라도,
// Billing 클래스의 코드는 전혀 수정할 필요가 없습니다. (OCP 준수)
}
}
Billing 클래스는 오직 License 인터페이스에만 의존합니다.
어떤 구체적인 라이선스 타입이든 calcFee()를 호출하여 처리할 수 있습니다.
LSP 위배 사례 1: 정사각형/직사각형 문제
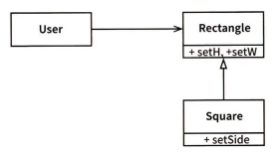
위는 LSP를 위배하는 유명한 예시 입니다.
Square(정사각형)는 각 변의 길이가 같아야 한다는 조건이 있기 때문에
Rectangle(직사각형)을 완전히 대체할 수 없습니다.
LSP와 아키텍처
- 초창기: 상속을 사용하도록 가이드하는 방법
- 현재: 인터페이스/구현체에도 적용되는 광범위한 설계 원칙
LSP 위배 사례 2: 아키텍처 관점
택시 파견 서비스를 통합하는 애플리케이션을 생각해봅시다.
고객은 택시 업체를 신경 쓰지 않고, 시스템은 REST 서비스로 선택된 택시를 파견합니다.
purplecab.com/driver/Bob
/pickupAddress/24 Maple St.
/pickupTime/153
/destination/ORD
모든 택시 업체가 pickupAddress, pickupTime, destination 필드를 동일하게 처리해야 합니다.
문제: ACME 택시 업체가 추가되는데 destination 대신 dest를 사용한다면?
if (driver.getDispatchUri().startsWith("acme.com"))
이런 예외 처리가 필요해지고, 이는 아래와 같은 단점을 초래합니다.
- 이해하기 힘든 온갖 종류의 에러 발생 가능
- 보안 침해 가능성
- 다른 택시 업체(Purple) 인수 시 if문 추가 필요
즉, 하위 인터페이스들끼리 서로 치환 가능하지 않습니다.
- Acme 기사 객체(S)는 PurpleCab 기사 객체(T)가 있어야 할 자리에 치환될 수 없습니다
- 때문에 클라이언트는 회사에 따라 다른 URI로 요청해야 합니다 (동일한 REST 서비스 호출 불가)
결론
LSP는 아키텍처 수준까지 확장해야 합니다.
치환 가능성을 위배하면 시스템 아키텍처가 오염됩니다.
ISP: 인터페이스 분리 원칙
유래
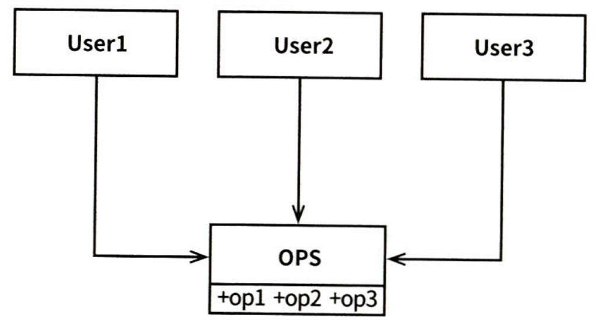
OPS가 정적 타입 언어로 작성된 클래스이고,
User1이 op2, op3를 사용하지 않을 때도 User1의 소스코드는 두 메서드에 의존합니다.
문제: op2가 변경되면 User1도 다시 컴파일 후 배포 필요
해결: 인터페이스 분리
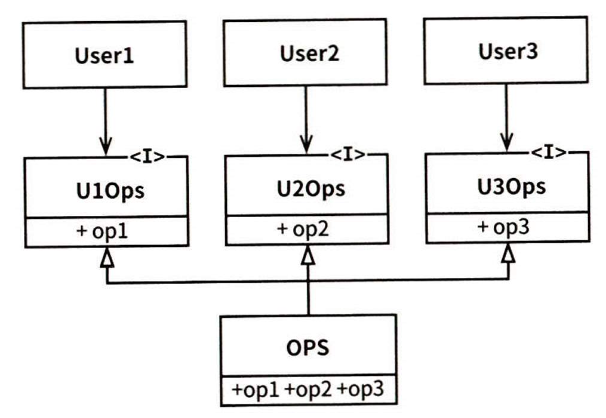
ISP와 언어
앞의 예제는 언어 타입에 의존합니다
정적 타입 언어
- import, use, include 같은 타입 선언문 사용
- 소스코드 자체에 포함된 선언 → 소스코드 의존성 발생 → 재컴파일 → 재배포
동적 타입 언어
- 선언문 존재 X → 런타임 추론
- 정적 타입 언어보다 유연하고 결합도가 낮은 시스템
하지만 ISP는 언어만의 문제가 아닙니다.
ISP와 아키텍처
ISP 사용의 근본적 동기
필요 이상으로 많은 걸 포함하는 모듈에 의존하는 것은 해롭습니다.
불필요한 재컴파일 및 배포 강제하기 때문입니다.
이는 아키텍처 수준에서도 동일하게 발생합니다.

- S 시스템은 F 프레임워크에 의존
- F는 D 데이터베이스를 반드시 사용
- S → F → D로 추이 의존성 발생
문제:
- F에서 필요하지 않은 기능이 D에 포함되었을 때, D 변경 시 F까지 배포 필요
- D 내부 기능 중 F, S에서 불필요한 기능에 문제가 생겨도 F, S까지 배포 필요
결론
불필요한 짐을 실은 무언가에 의존하면 예상치 못한 문제에 빠집니다.
DIP: 의존성 역전 원칙
DIP에서 설명하는 유연성이 극대화된 시스템은 소스코드 의존성이 추상에 의존하며 구체에는 의존하지 않는 시스템입니다.
use, import, include 구문은 인터페이스, 추상 클래스 같은 추상적인 선언만을 참조해야 합니다.
현실적인 접근
하지만 이는 규칙으로 보기엔 비현실적입니다. 시스템은 구체적인 많은 장치에 반드시 의존하기 때문입니다.
예를 들어 String은 구체 클래스이지만 추상 클래스로 만들려는 시도는 현실성이 없습니다.
String 클래스는 매우 안정적이고 변경될 일이 거의 없으며, 있더라도 엄격하게 통제되기 때문입니다.
우리가 피하고자 하는 것은 변동성이 큰 구체적 요소입니다.
안정된 추상화
- 추상 인터페이스 수정 → 구현체들도 따라 수정 필요
- 구체 구현체 수정 -X→ 추상 인터페이스는 수정할 필요 없음
즉, 인터페이스는 구현체보다 변동성이 낮습니다.
안정된 소프트웨어 아키텍처란,
변동성이 큰 구현체에 의존하지 않으며 안정된 추상 인터페이스를 사용하는 아키텍처라고 볼 수 있습니다.
구체적 코딩 실천법
- 변동성이 큰 구체 클래스를 참조하지 말 것
- 추상 인터페이스를 참조할 것
- 추상 팩토리 사용 강제
- 변동성이 큰 구체 클래스로부터 파생하지 말 것
- 상속을 신중하게 사용할 것
- 구체 함수를 오버라이드하지 말 것
- 구체 함수는 소스코드 의존성을 필요로 하므로, 오버라이드 시 의존성 제거 불가
- 차라리 추상 함수로 선언하고 구현체들에서 각자 구현
- 구체적이며 변동성이 크다면 절대로 그 이름을 언급하지 말 것
팩토리 패턴
대다수 객체 지향 언어에서 바람직하지 못한 의존성을 처리할 때 추상 팩토리를 사용합니다.
객체를 생성하기 위해서는, 그 객체를 임포트 하는 것이 필요하므로 구체적으로 정의한 소스 코드에 의존하게 됩니다.
팩토리 패턴은 객체를 어떻게 생성하는지에 대한 패턴입니다.

- 곡선: 아키텍처 경계 (구체/추상 분리)
- 추상 컴포넌트: 애플리케이션의 모든 고수준 업무 규칙 포함
- 구체 컴포넌트: 업무 규칙을 다루기 위해 필요한 모든 세부사항 포함
- 소스코드 의존성은 모두 한 방향(추상적인 쪽)을 향함
- 제어 흐름은 소스코드 의존성과 정반대 방향: 의존성 역전
구체 컴포넌트
위 예시에서 구체 컴포넌트에는 구체적 의존성이 하나 존재합니다. (ServiceFactoryImp → ConcreteImpl)
이는 DIP 위배하는 것이긴 하지만, 일반적으로 용인될 수 있습니다.
DIP 위배를 모두 없애는 것은 불가능하기 때문입니다.
다만, 위배 클래스들은 적은 수의 구체 컴포넌트 내부로 모을 수 있고, 나머지 부분과 분리할 수 있습니다.
예를 들어 Main 함수에서
- ServiceFactoryImpl의 인스턴스 생성
- 이 인스턴스를 ServiceFactory 타입으로 저장
- Application이 ServiceFactoryImpl 인스턴스에 접근
위와 같은 과정으로 코드가 흘러갈 때, Main에서는 ServiceFactoryImpl라는 구체 객체에 의존성을 갖게 됩니다.
# ========== 추상화 레이어 ==========
# service.py
class Service(ABC):
@abstractmethod
def do_something(self):
pass
# service_factory.py
class ServiceFactory(ABC):
@abstractmethod
def make_service(self) -> Service:
pass
# ========== 상위 레벨 (Application) ==========
# application.py
from service import Service
from service_factory import ServiceFactory
# ← ConcreteServiceImpl import 없음! ✅
class Application:
def __init__(self, factory: ServiceFactory):
self.service = factory.make_service()
def run(self):
result = self.service.do_something()
print(f"결과: {result}")
# ========== 하위 레벨 (구현체들) ==========
# concrete_service.py
from service import Service
class ConcreteServiceImpl(Service):
def do_something(self):
return "실제 작업 수행"
# factory_impl.py
from service_factory import ServiceFactory
from service import Service
from concrete_service import ConcreteServiceImpl # ← 하위가 하위에 의존 (괜찮음!)
class ServiceFactoryImpl(ServiceFactory):
def make_service(self) -> Service:
return ConcreteServiceImpl()
# ========== Main 컴포넌트 ==========
# main.py ← "더러운 일" 담당
from application import Application
from factory_impl import ServiceFactoryImpl # ← 여기서만 구체 클래스 알면 됨!
def main():
# 의존성 조립 (Dependency Injection)
factory = ServiceFactoryImpl()
app = Application(factory)
app.run()
if __name__ == "__main__":
main()
결론
DIP는 모듈 수준부터 고수준 아키텍처 수준까지 적용되며,
결국은 아키텍처 다이어그램에서 가장 눈에 드러나는 원칙이 될 것입니다.
위 예시의 추상/구체를 나누는 곡선의 경계는 곧 아키텍처를 나누는 경계가 될 것 입니다. (이후 장에서 소개 예정)
마치며
SOLID 원칙은 단순히 코드 레벨의 원칙이 아니라 아키텍처 수준까지 확장되는 설계 원칙입니다.
- SRP: 변경의 이유를 하나로 제한하여 응집성을 높입니다
- OCP: 확장 가능하면서도 기존 코드 수정을 최소화합니다
- LSP: 하위 타입이 상위 타입을 완전히 대체할 수 있어야 합니다
- ISP: 불필요한 의존성을 제거하여 영향 범위를 줄입니다
- DIP: 구체가 아닌 추상에 의존하여 유연성을 확보합니다
'클린아키텍처' 카테고리의 다른 글
| [클린 아키텍처] 2부 프로그래밍 패러다임 (0) | 2025.12.08 |
|---|
