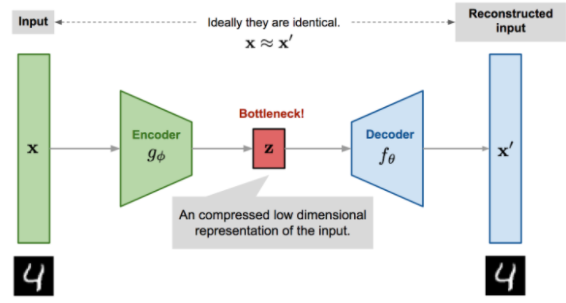
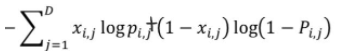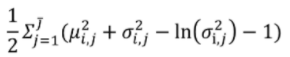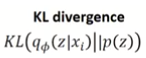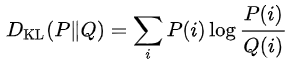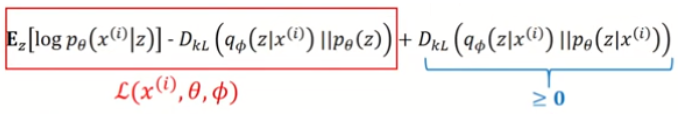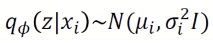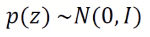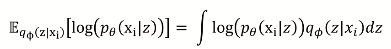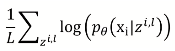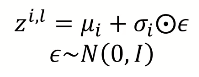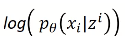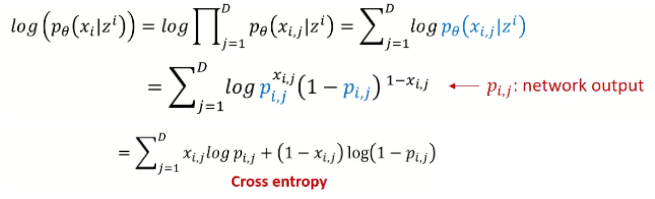비지도학습으로 입력 데이터의 표현을 효율적으로 학습할 수 있는 인공신경망 (feature extractor)
Encoder - z (latent variable) - Decoder 형태
output이 input의 형태로 나타나도록 하는 것이 목적이나, 그 과정에서 입력을 reconstruction해서 데이터를 효율적으로 representation 하는 방법 학습
차원을 축소(특징 추출)하기 위한 목적으로 만들어졌기 때문에 Encoder를 학습하기 위해 Decoder를 사용한 것으로 볼 수 있음
Variational Auto Encoder
Decoder를 사용하기 위해 Encoder 활용 (Decoder로 새로운 데이터를 생성하기 위함)
대략적인 동작 과정
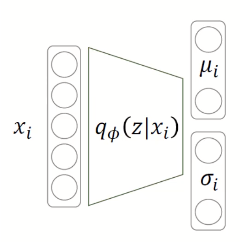
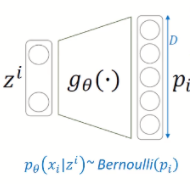
input 이미지 Encoder에 넣음
인코더를 거쳐 2개의 vector 평균과 표준편차를 output으로 배출
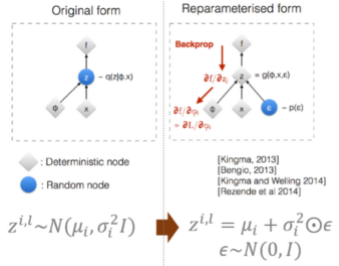
위의 평균과 표준편차를 통해 normal distribution 만듬
distribution에서 데이터 sampling 해서 z 생성 👉 Reparameterization Trick 사용→ NN에서 backpropagation 가능하게 하기 위함 → normal distribution을 단순히 sampling 했을 경우에는 미분이 불가하기 때문에 미분 가능한 식으로 바꿔줌
Decoder 통과
input과 비슷하게 복원된 output 배출
Auto Encoder vs. Variational Auto Encoder
AE
VAE
Encoder를 학습하기 위해 Decoder를 사용 → 차원 축소(특징 추출) 목적
Decoder를 사용하기 위해 Encoder 활용 → 새로운 데이터 생성 목적
Encoder → z (latent vector)
Encoder → 평균, 표준편차 vector 배출 → normal distribution → sampling → z(latent vector)
Loss Function
아래 두가지 function의 합으로 나타냄
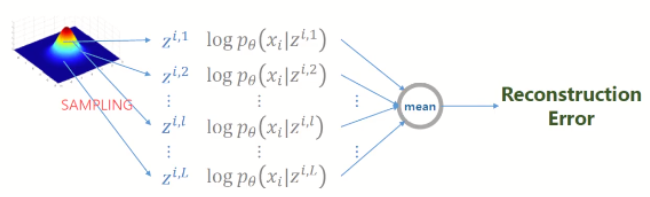
Reconstruction Error
input과 output의 차이를 최소화 하는 것
normal distribution의 경우 MSE, bernoulli distribution의 경우 Cross entropy로 나타남 → VAE는 기본적으로 bernoulli를 따르는 Decoder 사용
Regularization
VAE는 normal distribution을 만들어 sampling하기 때문에 z는 normal distribution을 따른다는 가정이 들어가있음
그 과정을 최적화에 넣기 위해, encoder를 통과해서 나오는 z 값의 확률분포와 정규분포와의 거리가 최소가 되도록 KL divergence 최소화
Regularization 식을 KL divergence로 변환하면 아래와 같음
👉 KL divergence → 두 확률 분포의 차이를 계산하는데 사용하는 함수
How to train ? (x가 input data)
VAE는 기본적으로 Decoder를 위한 것이기 때문에 위처럼 z가 있으면 x를 만들어내기 위한 목적이 있음
training data의 likelihood(가능도)를 최대화 → 즉, x가 나올 확률 p(x) 가 가장 커지는 distribution을 만들고자 함
원래는 Decoder만 있으면 되지만, z에 대한 x를 뽑아내서 학습을 시키는 게 수식적으로 intractable해서 Encoder를 정의함
p(x)의 최대를 구하기 위해 log(p(x))의 최대를 구해도 됨→ z가 encoder의 q(z|x) distribution을 따를 때 log(p(x))의 기대값을 구함 → 베이즈 정리 + 수식 계산 → KL divergence 형태로 나타냄
정리하면, 아래의 식 maximize
첫번째 항 : decoder를 통해 복원될 수 있도록 만들어주면 됨
두번째 항 : encoder를 통과한 확률 분포가 z의 분포와 비슷하게 만들어주면 됨
세번째 항의 경우 : x → z 방향의 조건부 확률 값은 intractable 하고 KL divergence 값 자체가 0 이상이라는 것만 알 수 있음
즉, 빨간 박스 부분(ELBO)을 maximize 하면 됨
→ θ는 decoder의 파라미터, Φ는 encoder의 파라미터
최종 Loss function 도출
Reconstruction Error : x가 Encoder(Φ라는 network) 지나서 z가 나오고, 해당 z를 Decoder(θ라는 network)에 넣었을 때 x가 나올 확률 maximize